Uni-Codes und japanische Schriftzeichen
Nicht-kompatible Kodierungen erschweren die Datenmigration aus unterschiedlichen Systemen
Unterschiedliche Kodierungen sind wesentliche Fehlerquellen von Problemen bei der Datenmigration. Dazu zählen sowohl Zeichencodes wie UTF-8 und ASCII, also auch unterschiedliche Alphabete wie sie beispielsweise im Japanischen verwendet werden. Werden Datensätze aus verschiedenen Systemen zusammengeführt, so müssen diese daher vor der Migration bereinigt und umkodiert werden. Die Datenqualitätstools des Stuttgarter Softwarespezialisten TOLERANT Software können hierbei unterstützen, da sie Texte aus unterschiedlichen Schriftsystemen lesen und auswerten können.
Daten können in unterschiedlichen Zeichencodes kodiert werden. Ein international gängiger Zeichencode ist der auf 8-Bit kodierte Uni-Code UTF-8. In diesem Standard ist für jedes Textelement aller bekannten Schriftkulturen und Zeichensystemen ein bestimmter Code festgelegt. Die Gesamtzahl der im UTF-8 definierten Zeichen beträgt 28 = 256 Zeichen. Ein Vorgänger und immer noch weit verbreiteter Zeichencode ist der auf 7-Bit kodierte ASCII-Code, der 27 = 128 Zeichen darstellen kann. Probleme treten dann auf, wenn UTF-8 kodierte Datensätze in eine ASCII-kodierte Datenbank integriert werden. Der ASCII-Code kann die integrierten Datensätze dann nicht auslesen und folglich Dubletten nicht erkennen.
Doppelt erfasst?
Dubletten oder Duplikate sind Datensätze, die in einer Datenbank doppelt auftauchen. Die Dublettenerkennung ist eine unabdingbare Komponente, die bei der Zusammenführung von Daten berücksichtigt werden muss, denn nur so können Datenqualitätsprobleme wie die doppelte Erfassung von Kunden verhindert werden. Doppelt geführte Kunden, die z.B. eine Rechnung mehrfach erhalten, sind ansonsten schnell verärgert und drohen abzuwandern. Um dem vorzubeugen, sollte bereits vor der Datenmigration darauf geachtet werden, dass die Datenkodierungen kompatibel sind. Andernfalls müssen sie vor der Migration umkodiert werden.
So werden Daten aufbereitet
In einem sogenannten ETL-Prozess werden die Rohdaten vor der Migration aufbereitet und wahlweise in eine ASCII-Datei oder in eine UTF-Datei überführt. Die Abkürzung ETL bezeichnet die drei Datenmigrations-Prozesse Extraktion (E), Transformation (T) und Laden (L), die üblicherweise durchlaufen werden, wenn Daten von einem System ins andere überführt werden. ETL-Prozesse sind batch-orientiert, d.h. sie laufen jeweils nur in einem zuvor definierten Zeitraum ab und bereiten einen begrenzten Umfang von Datensätzen auf. Die Datenaktualität von ETL-Prozessen ist daher begrenzt.
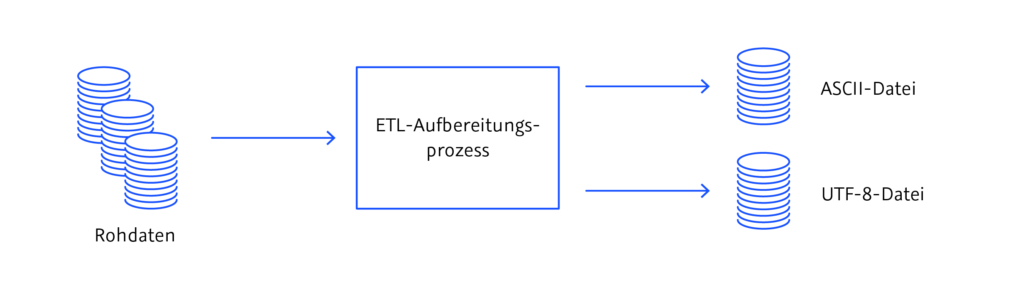
Während des Aufbereitungsprozesses werden die Daten extrahiert (E), transformiert (T) und geladen (L). Abbildung: © TOLERANT Software
Japanische Dubletten
Dubletten entstehen aber nicht nur durch unterschiedliche Kodierungen; sie können auch kulturell bedingt sein. Im Japanischen gibt es beispielsweise drei Alphabete und alle drei werden in japanischen Texten kombiniert verwendet. Wörter chinesischen Ursprungs werden üblicherweise im Symbol-Alphabet Kanji geschrieben, grammatikalische Wörter wie beispielsweise Präpositionen oder Verb-Endungen werden im Hiragana-Alphabet notiert und für Fremdwörter aus dem Englischen verwenden Japaner das Katakana-Alphabet. Da die Aussprache der Kanji-Zeichen selbst für Muttersprachler nicht immer eindeutig ist, werden in Kanji notierte Namen oftmals zusätzlich in die Silbenalphabete Hiragana oder Katakana transkribiert. Ähnlich wie beim Uni-Code entstehen Dubletten in japanischen Datensätzen dann, wenn transkribierte Namen nicht ihren Kanji-Entsprechungen zugeordnet werden. Anhand von drei Beispielen stellen wir vor, welche Herausforderungen die japanische Sprache für die Datenmigration bereithält und wie Dubletten dabei entstehen können.
Fünf Schreibweisen für ein und denselben Namen
Ein Beispiel ist der Name 髙橋 眞國 (Takahashi Makuni). Das erste Kanji-Zeichen 髙 ist in diesem Beispiel in einer traditionellen Kanji-Variante notiert, wie sie beispielsweise im Familienregister verwendet wird. Maschinenabhängig kann das Kanji-Zeichen, leicht abweichend davon, auch so 高 geschrieben werden. Auch für die traditionellen Kanji-Zeichen 眞國 im zweiten Teil des Namens gibt es eine moderne Entsprechung, die so 真国 aussieht. Im Silbenalphabet Katakana würde der komplette Name als タカハシ マサクニ transkribiert, und im Silbenalphabet Hiragana sähe er soたかはし まくにaus. Bei der Datenmigration kommt es nun darauf an, die insgesamt 5 unterschiedlichen Datensätze desselben Namens (also traditionelles Kanji, modernes Kanji, Katakana, Hiragana und letztendlich die in lateinischen Buchstaben geschriebene Variante) so zu verlinken, dass sie – unabhängig von der Dateneingabe – stets wiedergefunden und richtig zugeordnet werden. Die Folge einer fehlenden Verlinkung wären fünf Dubletten.
Fehlertolerante Dublettenerkennung
Eine weitere Herausforderung der japanischen Schrift stellt die unscharfe oder fehlertolerante Dublettenerkennung dar. Eine Suche ist dann unscharf oder fehlertolerant, wenn Dubletten auch bei einer fehlerhaften Dateneingabe (wie z.B. bei Buchstabendrehern, Tippfehlern oder minimalen Abweichungen in der Schreibweise) gefunden werden. Die japanische Schrift unterscheidet neben drei unterschiedlichen Alphabeten teilweise auch Groß- und Kleinschreibung. Wenn die Hiragana-Laute よ(yo)、や (ya) undゆ (yu) sowie die Katakana-Lauteヨ (yo)、ヤ (ya) und ユ(yu) mit einem Konsonant verschmelzen, dann werden sie in etwas kleinerer Schriftgröße geschrieben. Ein Beispiel ist der Name 中島 京子 (Nakashima Kyoko), der in Hiragana als なかしま きょこtranskribiert wird und in Katakana als ナカシマ キョウコ. Die Zeichen ょ und ョ folgen auf きbzw. キund sind daher etwas kleiner geschrieben. Werden diese Zeichen in Großbuchstaben geschrieben, so würde der Name aus dem obigen Beispiel fehlerhaft in „Nakashima Kiyoko“ transkribiert werden. Die Herausforderung bei der Datenmigration japanischer Datensätze besteht folglich darin, Dubletten auch bei leichten Abweichungen in der Schreibweise (wie beispielsweise bei der Groß- und Kleinschreibung) zu erkennen und dennoch den richtigen Kanji-Zeichen zuzuordnen.
Unterschiedliche Kanji-Lesarten
Besonders herausfordernd für die japanische Dublettenerkennung sind schließlich die unterschiedlichen Lesarten von Kanji-Zeichen. So kann der Name 東海林太郎 beispielsweise entweder als Shouji Tarō oder als Taorin Tarō gelesen und ausgesprochen werden. Um die Aufgabe der Datenmigration erfolgreich zu meistern, müssen Datenqualitätstools in der Lage sein, die Katakana-Transkription ショウジ タロウ (Shouji Tarō) und die Variante トウカイリン タロウ(Taorin Tarō) als unterschiedliche Lesarten desselben Kanji-Zeichens zu identifizieren und als Dubletten zu erkennen.
Fazit
Probleme bei der Datenmigration lassen sich vermeiden, indem Datensätze aus unterschiedlichen Datenbanken vor der Zusammenführung geprüft werden. Inkompatible Zeichenkodes müssen vor der Datenmigration mit Hilfe von ETL-Prozessen bereinigt und ggf. umkodiert werden. Datenqualitätswerkzeuge, die alle drei japanischen Schriftsysteme beherrschen und auslesen können, helfen dabei, Fehler bei der Datenmigration zu vermeiden. Der Datenqualitätsspezialist TOLERANT Software ist auf unterschiedliche Schriftsysteme und Kodierungen in vielen Ländern und Kulturkreisen spezialisiert. Die Datenqualitätstools von TOLERANT Software beseitigen die sprachlich bedingten, spezifischen Probleme inkompatibler Kodierungen in vielen unterschiedlichen Ländern und Kulturkreisen.

